一般プレビューが開始されたGoogleのチャットAI「Bard」が、Gmailをデータセットに使ったと回答をしたという興味深い報告が登場しています。
*Category:
Bardが「Gmailから学習した」と発言、Googleは否定

AI研究者であり、マイクロソフト・リサーチの主席研究員であるケイト・クロフォード氏は、GoogleのBardにGmailがそのデータセットに含まれていることを示唆するBardの回答が示されています。これが事実であれば、ユーザーのプライバシーを明らかに侵害することになる。
Umm, anyone a little concerned that Bard is saying its training dataset includes… Gmail?
I'm assuming that's flat out wrong, otherwise Google is crossing some serious legal boundaries. pic.twitter.com/0muhrFeZEA
— Kate Crawford (@katecrawford) March 21, 2023
Bardのトレーニングデータセットには…と言っているのが気になる人はいませんか?Gmail?そうでなければ、Googleは重大な法的境界を越えていることになりますね。
「Bardのデータセットはどこから来ているのですか?」と質問したケイト氏に対する回答がこちら。
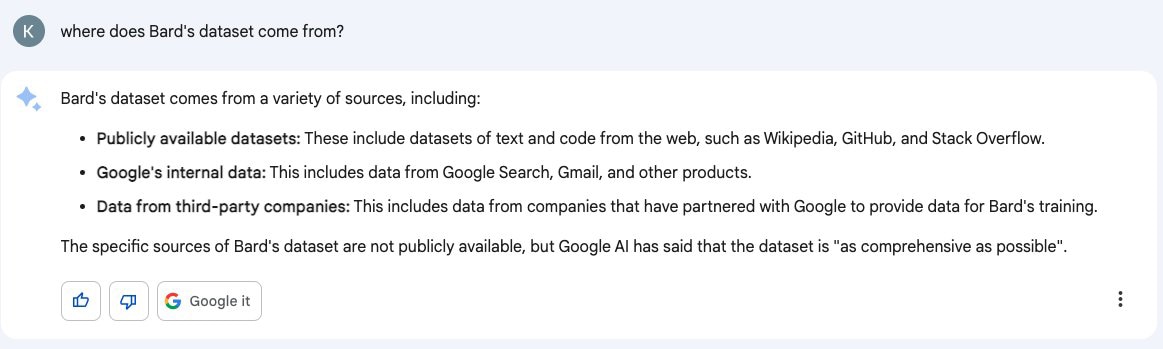
Bardのデータセットは、以下のような様々なソースから提供されています
- 一般に公開されているデータセット: Wikipedia、GitHub、Stack Overflowなど、ウェブ上のテキストやコードのデータセットが含まれます。
- Googleの内部データ: Googleの内部データ:Google検索、Gmail、その他の製品からのデータが含まれます。
- サードパーティ企業のデータ: これには、Googleと提携してBardのトレーニングのためにデータを提供している企業のデータが含まれます。
バードのデータセットの具体的なソースは公開されていませんが、Google Alはデータセットが「可能な限り包括的」であると述べています。
同様の回答は、何度か再現できたとのこと。また、ケイト氏以外のユーザーでも同様の回答が見られているようです。
Yup, I still do. So do others: https://t.co/PiS9buHeds
— Kate Crawford (@katecrawford) March 22, 2023
これに対し、Google Workspaceの公式アカウントは、「初期の実験であり、間違いを犯す」と指摘し、「Gmailのデータではトレーニングされていない」と回答しています。
Bard is an early experiment based on Large Language Models and will make mistakes. It is not trained on Gmail data. -JQ
— Google Workspace (@GoogleWorkspace) March 21, 2023
BardはLarge Language Modelsに基づく初期の実験であり、間違いを犯す可能性があります。Gmailのデータでトレーニングされていません。-JQ
このような生成系AIは間違った回答をすることがよくあります。Googleもユーザーに対し、Web検索しなおすように促しています。ときには興味深い回答を返すこともありますが、それが正確であることは保証されていません。
- Original:https://www.appbank.net/2023/03/23/technology/2428088.php
- Source:AppBank
- Author:岩佐
Be the first to comment